
AIツールの導入が進むほど、次に必ずぶつかるのが「本番運用の壁」です。
動いていたはずのエージェントが、ある日から急に壊れる。コストだけが増える。出力の品質が日によってブレる。
この問題は、モデルが賢くなるほど増えます。理由は単純で、判断や分岐が増え、外部連携が増え、失敗パターンが増えるからです。
だから今、注目すべきは「何のLLMを使うか」ではなく、壊れないための運用設計と、そのためのAgentOpsツール群です。
- この記事の独自テーマ:AgentOpsは「4レイヤー」で考えると速い
- まず知っておくべき「壊れ方」7パターン
- 注目ツール7選:AgentOpsの現場で実際に効くやつだけ
- 1) LiteLLM(Gateway)
- 2) Langfuse(Tracing + Prompt Ops)
- 3) LangSmith(Tracing + Evaluation)
- 4) Phoenix(Arize Phoenix)(Tracing + Evaluation)
- 5) Helicone(Tracing + Cost)
- 6) Braintrust(Evaluation)
- 7) PromptLayer(Prompt Ops)
- おまけ:W&B Weave(開発者向けの計測と評価の道具箱)
- 独自テンプレ:AgentOps Scorecard(これだけ埋めると改善が進む)
- 7日間で最低限を作る導入計画
- 結局どれから入れる?迷った時の即決ルール
- まとめ
この記事の独自テーマ:AgentOpsは「4レイヤー」で考えると速い
AgentOpsの道具はごちゃ混ぜで紹介されがちですが、実務では次の4レイヤーに分けると迷いが減ります。
この分類で読むと、自分の詰まりポイントに最短で刺さります。
- Gateway:全LLM呼び出しを一元化し、キー管理と予算制限をかける
- Tracing:どこで何が起きたかを追跡し、会話やエージェントの流れを再現する
- Evaluation:品質を数値化し、回帰を検知し、改善サイクルを回す
- Prompt/Knowledge Ops:プロンプトと仕様をバージョン管理し、関係者で更新できる状態にする
まず知っておくべき「壊れ方」7パターン
AgentOpsが必要になるのは、次のどれかが起き始めた時です。
該当が多いほど、いまが導入タイミングです。
- 再現できない不具合:ユーザー報告はあるが、ログがなく原因が追えない
- 品質の揺れ:同じ入力でも日によって精度が変わる
- 地味な劣化:プロンプトや外部データ更新で、少しずつ悪くなる
- ツール連携事故:外部APIや権限で失敗し、無限リトライや二重実行が起きる
- コスト爆発:長文化、再試行、無駄な呼び出しで請求だけ伸びる
- セキュリティ不安:誰がどのキーでどのデータに触れたか分からない
- 改善できない:良い悪いが感想戦になり、改修の優先度が決められない
注目ツール7選:AgentOpsの現場で実際に効くやつだけ
ここからは、上の4レイヤーに沿って紹介します。
各ツールは「一言結論」「刺さる場面」「最短の入り方」だけに絞ります。
1) LiteLLM(Gateway)
一言結論:LLM呼び出しの入口を統一して、予算とキー管理を握るためのAI Gateway。
刺さる場面
・複数のLLMプロバイダを使い分けたい(OpenAI系、他社モデル、ローカルなど)
・チームやプロダクト別に予算制限をかけたい
・ログ収集の方式を統一したい(後述のTracingへ渡す)
最短の入り方
1)まずは全リクエストをProxy経由にして、呼び出し経路を一本化
2)プロジェクト別キーを発行し、上限とアラートだけ先に付ける
3)後からキャッシュやルーティングを足していく
2) Langfuse(Tracing + Prompt Ops)
一言結論:オープンソースで始めやすい、トレースとプロンプト運用の土台。
刺さる場面
・まずは「何が起きたか」を追える状態にしたい
・セルフホストで運用したい、または将来オンプレも見据えたい
・プロンプトやバージョン管理をチームで回したい
最短の入り方
1)SDK導入でトレースを出す(まずは会話単位)
2)失敗ケースにタグとメモを付ける運用を始める(ここが効く)
3)プロンプトをバージョン管理して、変更理由とセットで残す
導入のコツ
「全てのリクエストを記録」から始めない方がうまくいきます。
まずは重要フロー(決済、問い合わせ、生成のコア)だけに絞り、運用が回ったら広げるのが安全です。
3) LangSmith(Tracing + Evaluation)

一言結論:トレースと評価をセットで回して、改善サイクルを作るなら強い。
刺さる場面
・LangChainやLangGraph周辺で開発している
・評価用データセットと回帰テストを回したい
・コストや失敗の原因をトレースで追いたい
最短の入り方
1)重要チェーンだけトレースして、失敗例を集める
2)評価データセットを作り、変更前後で比較する
3)改善したら評価を定期実行にして「戻り」を検知する
4) Phoenix(Arize Phoenix)(Tracing + Evaluation)
一言結論:オープンソースで「実験と評価」を回したい人向けの選択肢。
刺さる場面
・まずは無料で評価と可視化を始めたい
・チーム内で実験と検証の文化を作りたい
・LLMアプリのトラブルシュートを体系化したい
最短の入り方
1)トレースの導線を作り、失敗例を可視化する
2)まずは簡単な評価軸(正答、禁止語、根拠の有無)から始める
3)RAGなら、検索ヒットと回答の関係を見て改善する
5) Helicone(Tracing + Cost)

一言結論:Proxy型の導入で、コストと挙動の見える化を速くやるなら候補。
刺さる場面
・SDKを深く組み込みたくない、まずはProxyで計測したい
・コスト最適化の優先度が高い(どこで無駄が出ているか見たい)
・モデルやプロバイダを切り替えながら運用したい
最短の入り方
1)Proxy経由にして計測を開始
2)高コストのエンドポイントから改善する(長文化、再試行、無駄呼び出し)
3)キャッシュやルーティング方針を決める
6) Braintrust(Evaluation)

一言結論:評価とスコアリングを中心に、品質改善を回すためのプラットフォーム。
刺さる場面
・プロンプト改善が属人化していて、評価基準が欲しい
・社内の関係者に「改善した根拠」を見せたい
・回帰を早めに検知して、安心して更新したい
最短の入り方
1)まずは「良い例」「悪い例」を20件集める
2)採点基準を2つだけ決める(例:正確性、実用性)
3)更新のたびに同じセットで回帰チェックする
7) PromptLayer(Prompt Ops)
一言結論:プロンプトとエージェントの変更を「見える化」して、チームで回すワークベンチ。
刺さる場面
・プロンプトがコードの奥に埋もれて、誰も触れない
・ドメイン担当が改善したいのに、開発待ちになる
・変更履歴と結果を紐づけて管理したい
最短の入り方
1)主要プロンプトだけをテンプレ化して管理する
2)変更理由と期待効果を必ず残す(ここが回帰対策になる)
3)小さな評価セットで、変更の良し悪しを即判定する
おまけ:W&B Weave(開発者向けの計測と評価の道具箱)
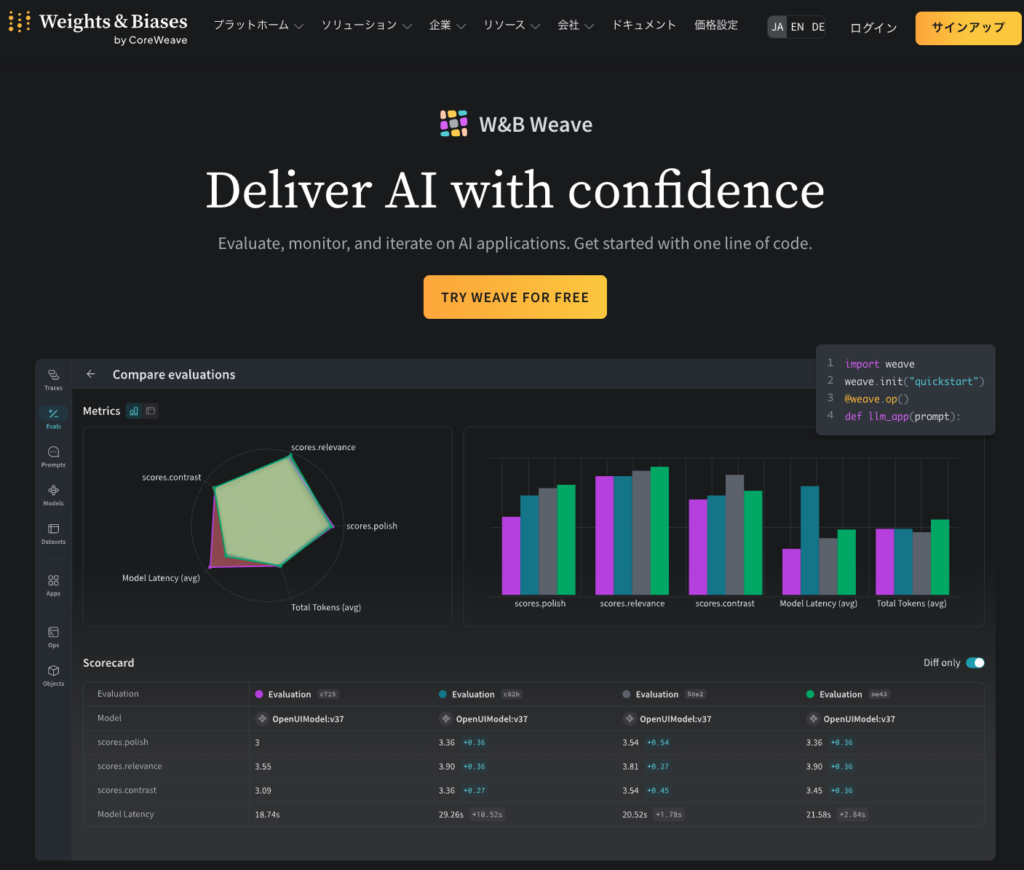
Weaveは、生成AIアプリの入出力ログやデバッグなど、開発寄りの運用に刺さります。
すでにW&Bを使っているチームなら、評価やログを同じ土俵で扱いやすいのがメリットです。
独自テンプレ:AgentOps Scorecard(これだけ埋めると改善が進む)
ツールを入れても、見るべき項目が決まっていないと結局放置されます。
以下のスコアカードを、まずは週1で埋める運用にすると、改善が進みます。
AgentOps Scorecard(週次)
1) 成功率:主要フローの完了率(%)
2) 品質:人手評価 or 自動評価の平均スコア(例:1-5)
3) 根拠:根拠リンク付き回答の比率(RAGなら特に)
4) 速度:p95 レイテンシ(秒)
5) コスト:1セッションあたり平均コスト(円 or $)
6) 事故:インシデント件数(再現できたかも含む)
7) 改善:今週の変更点と、評価結果の差分7日間で最低限を作る導入計画
- Day1:重要フローを1つ決める(問い合わせ返信、要約、分類など)
- Day2:Tracingを入れる(LangfuseかLangSmithかPhoenix)
- Day3:失敗例を10件集め、タグ付けルールを決める
- Day4:評価軸を2つ決め、簡単な回帰セットを作る(20件)
- Day5:Prompt Opsを開始(PromptLayerやLangfuseのプロンプト管理)
- Day6:コストの上位要因を1つ潰す(長文化、再試行、無駄呼び出し)
- Day7:Scorecardを埋めて、次の改善を1つだけ決める
結局どれから入れる?迷った時の即決ルール
- とにかく早く可視化したい:Helicone(Proxy型)
- 無料かセルフホストから始めたい:Langfuse or Phoenix
- 評価まで含めて改善を回したい:LangSmith or Braintrust
- プロンプト運用が属人化している:PromptLayer(またはLangfuseのPrompt管理)
- 複数プロバイダを使い分けたい:LiteLLM(入口統一)
まとめ
AIエージェントは「作った瞬間がピーク」になりがちです。
本当に差が出るのは、壊れ方を先に想定し、計測し、評価し、更新を回すAgentOpsです。
まずはTracingを入れて、失敗例を集め、週次Scorecardで改善を回す。ここから始めるのが最短です。

